Алгоритм Хаффмана — жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью. Был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы. В настоящее время используется во многих программах сжатия данных.
В отличие от алгоритма Шеннона — Фано, алгоритм Хаффмана остаётся всегда оптимальным и для вторичных алфавитов m2 с более чем двумя символами.
Этот метод кодирования состоит из двух основных этапов:
Построение оптимального кодового дерева.
Построение отображения код-символ на основе построенного дерева.
Содержание 1 Кодирование Хаффмана
2 Адаптивное сжатие
3 Биграммная модель
4 Переполнение
5 Масштабирование весов узлов дерева Хаффмана 5.1 Выигрыш от масштабирования 6 Применение
7 Модификации
8 Примечания
9 Литература
10 Ссылки
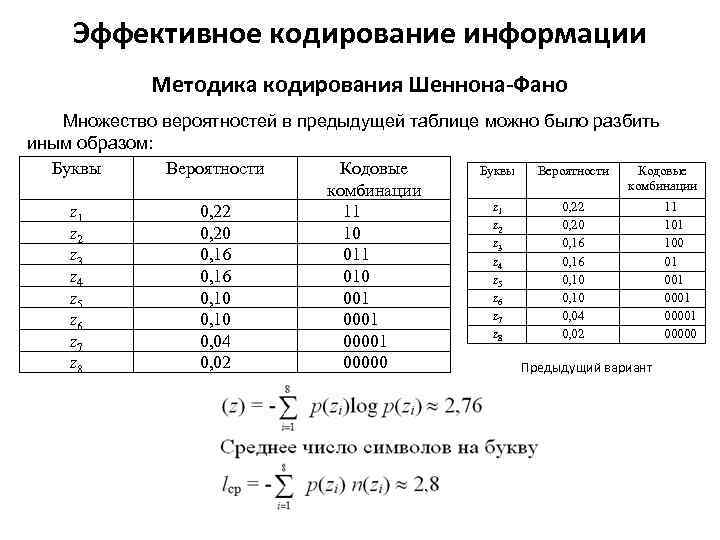
Сжатие данных методами Хафмана и Шеннона-Фано